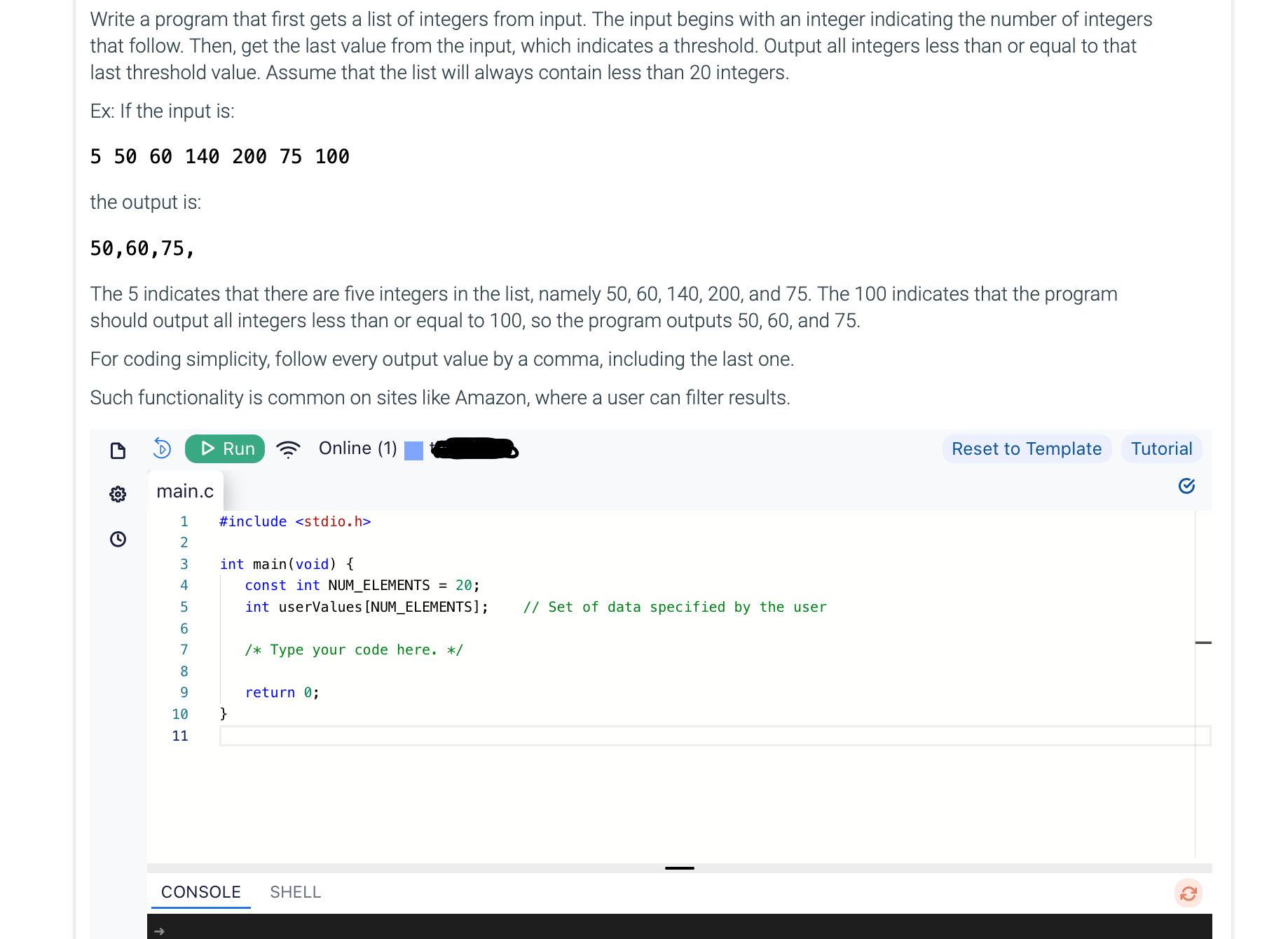
Understanding Token Limits in AI Models
When interacting with large language models (LLMs), users often encounter a common issue: truncated output due to token limits. These limits are in place to prevent the model from consuming excessive computational resources and to ensures that responses are generated within a reasonable timeframe. In this article, we will explore the concept of token limits, their impact on LLM output, and how to work around them.
What are Token Limits?
Tokens are the fundamental unit of text processed by LLMs, including words, punctuation, and subwords. When you interact with a model, your input, as well as the response generated by the model, is composed of tokens. Token limits dictate the maximum number of tokens that can be processed in a single request, including both the input and the output. This limit is essential to preventing the model from consuming excessive resources and to ensuring that responses are generated within a reasonable timeframe.
Token limits can have a significant impact on the quality and completeness of the output generated by LLMs. When the token limit is reached, the model may truncate the response, leaving out important information or context. This can lead to incomplete or inaccurate responses, which can be frustrating for users.
Below is the continuation of the list, the initial output was truncated for brevity and due to special tokens.
Models and Tokens Window
Understand the token limit of your LLM model

Furthermore, visual representations like the one above help us fully grasp the concept of Below Is The Continuation Of The List, The Initial Output Was Truncated For Brevity And Due To Special Tokens..
Adjust your input to avoid token truncation
One way to avoid token truncation is to adjust your input to fit within the token limit. This can be achieved by summarizing your request or question, using concise language, and avoiding unnecessary details. By doing so, you can ensure that the model has enough tokens left to generate a complete and accurate response.
Use continuation token
API-specific Considerations
Below is the continuation of the list, the initial output was truncated for brevity and due to special tokens.
Check Max_Token setting
The max_tokens setting is crucial in determining the output token limit. Make sure to set this parameter correctly to avoid token truncation. For example, in some cases, the default max_tokens may be set too low, leading to truncated responses.

Set the context window correctly
The context window refers to the total number of tokens the model can process, including both the input and the output. Ensure that you set the context window correctly to avoid token truncation and expired requests.
Break up long requests
When dealing with long requests or complex interactions, consider breaking them down into smaller chunks. This can help you avoid token truncation and ensure that the model can process your requests efficiently.
Conclusion
Understanding token limits is essential to getting the most out of LLMs. By grasping the concept of tokens and their impact on LLM output, you can develop strategies to avoid token truncation and generate more accurate and comprehensive responses. Remember to adjust your input, use continuation tokens, and check API-specific settings to optimize your interactions with LLMs.
Below is the continuation of the list, the initial output was truncated for brevity and due to special tokens.
Test and refine your approach
Experiment with different token settings, input formats, and continuation tokens to refine your approach and achieve optimal results. By doing so, you can ensure that your LLM interactions are smooth, efficient, and productive.
Stay up-to-date with model updates
LLMs are continuously evolving, and new models with different token limits and capabilities are emerging. Stay informed about updates and improvements to ensure that you can leverage the potential of LLMs to its fullest extent.
Final Tips
Maximize Your LLM Experience
By understanding and working with token limits, you can unlock the full potential of LLMs and achieve better results from your interactions. By being informed about token limits, you can adjust your workflow, input, and output to ensure smooth and effective communication with LLMs.
![[BUG]:](https://ai2-s2-public.s3.amazonaws.com/figures/2017-08-08/e019f7fc2583204574f6631f3297439f79a5dc28/6-Figure2-1.png "[BUG]:")
![View of [Question] Are messages always truncated to last - GitHub](https://www.researchgate.net/profile/Ashmita-Gupta-6/publication/353375378/figure/fig1/AS:11431281121175326@1676869819743/Change-in-output-tariff-and-initial-output-tariff-in-1988_Q640.jpg "[Question] Are messages always truncated to last - GitHub")


![Image showcasing ChatGPT Response Cut Off [Solved] - ApproachableAI](https://lookaside.fbsbx.com/lookaside/crawler/media/?media_id=724345457174345 "ChatGPT Response Cut Off [Solved] - ApproachableAI")







")


+statement:.jpg "Output truncated without reason - General - vLLM Forums")










